
Background
In Fall 2018, I joined Zhile Ren and Frank Dellaert on the SUMO Challenge by Facebook.
The SUMO Challenge has several tracks for which we can compete for the best results, so our team decided to compete for the 3D Bounding Box track. That is, given 360 Degree RGB-Depth images, can we determine the 3D oriented bounding box for each of the items in the given scene?
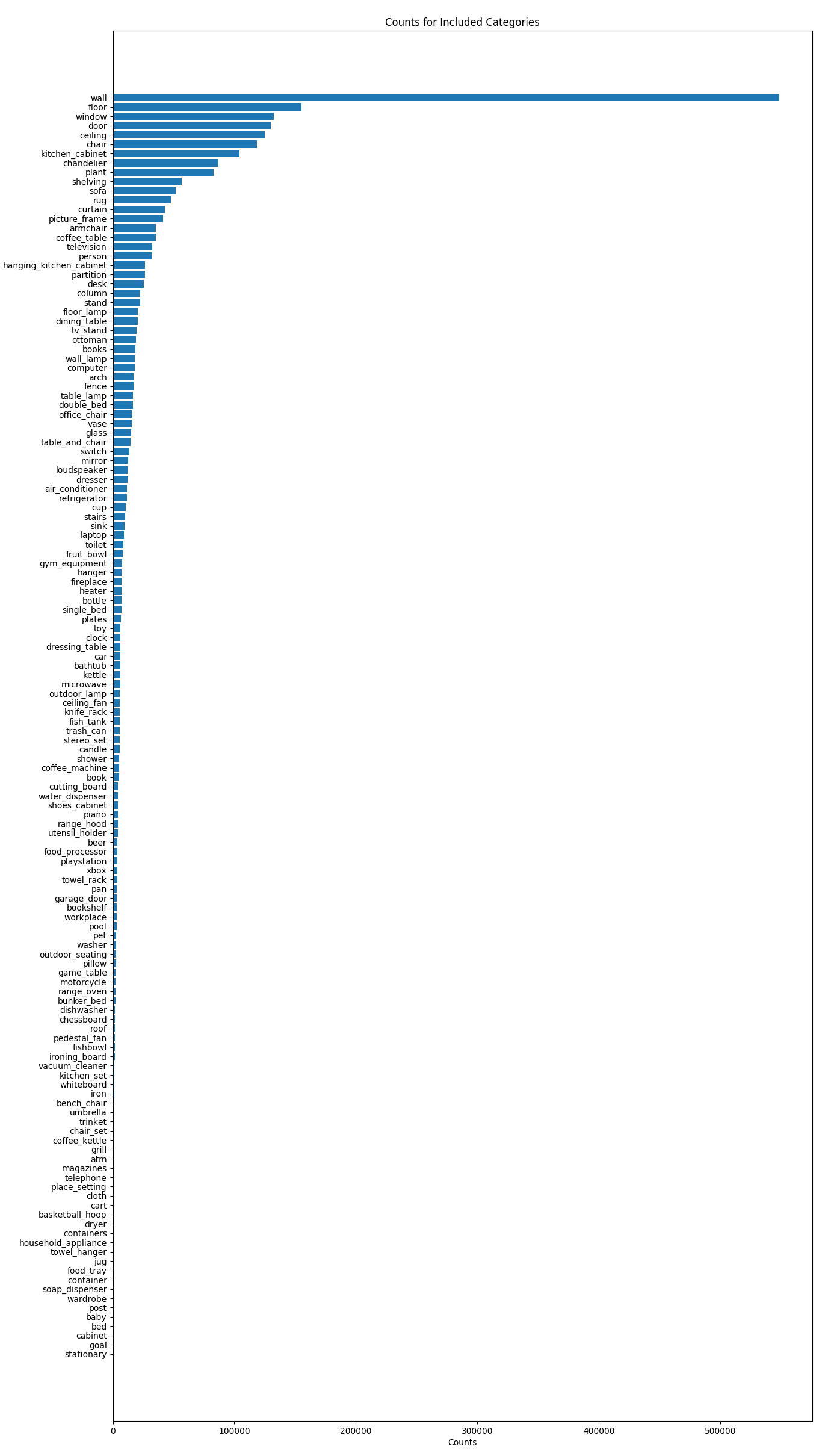
There are over 100 included object categories, with a pretty skewed distribution:
Approaches
At first, Zhile and I were determined to use direct 3D detection approaches like using Clouds of Oriented Gradients (CoG). However, the enormous size of the dataset (1+ Terrabyte) and image sizes (1024 x 6144 x 3 channels) immediately became problematic, both for training and inference.
CoGs are great when the shape of the categories are easy to discern (i.e shapes that are not predominantly “box-like”), but in SUMO, we had many items that would have taken on very similar CoGs such as single_bed versus double_bed, tv_stand versus dresser, and so on.
We decided a good starting point would be to determine object locations in the 2D space, and see where we could go from there. We intended to then train for CoGs, but we had limited time with the SUMO challenge deadline being mid-December, so we decided to see how well we could perform by using the following pipeline:
- Project 3D bounding boxes into 2D space to generate a 2D dataset
- Train a Faster-R-CNN network to detect objects on the 2D dataset
- Project the 2D coordinates back into 3D, do some simple post-processing to prevent things like walls and floors from being in the bounding box
- Train Regressors to help correct the coordinates on a per-category basis
Results
On December 18th, we found out that the SUMO challege deadline would be pushed back to January 14th. We continued work on step (3) but didn’t get very far in step (4), so our final pipeline consists of steps (1) through (3). We made our submission on Sunday, January 13th.
We found out that we were narrowly beat by the Princeton Vision Lab for 1st place, leaving us in 2nd place for our cateogry.
Visual Results in 3D
Below are our results in the 3D space. On the left, we have a red bounding box, which is our detection. On the right in green we have the ground truth bounding boxes for that same scene.

television with books in the tv stand. 
shower. 
door. Visual Results in 2D
Below are some visual results we’ve gotten in the 2D space training the Faster-R-CNN network.
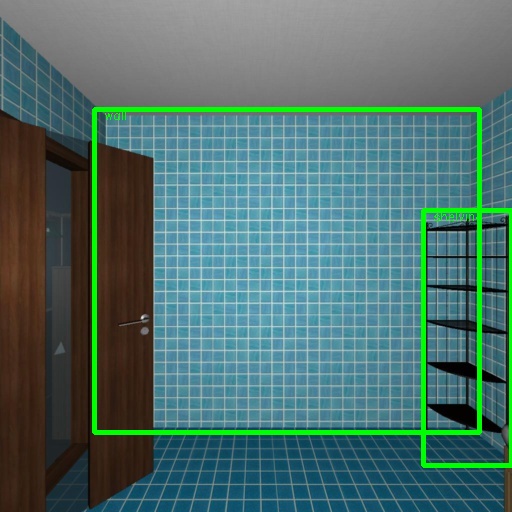



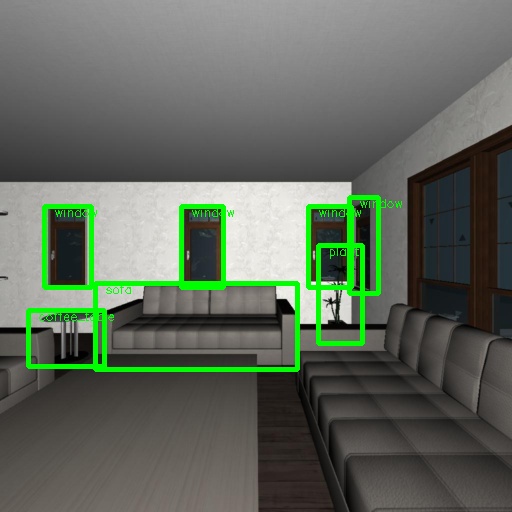
As you can see, the network performs fairly well. Mean AP was about 23% which is reasonable given the enormous dataset size and the skewed distribution. One aspect that particularly complicates this challenge are the walls and floors, which are object categories, but the coordinates are often outside of single-frame views, which is exactly what this network was trained to perform on.